Welcome to Sumo Notebooks’s documentation!¶
Sumo Notebooks provide a way to seamlessly access data stored in Sumo for the purpose of data exploration and statistical analysis. The notebooks provide an interactive way to gain and share insights of a dataset. Built on top of Apache Zeppelin and Jupyter, Sumo Notebooks provide a state-of-the-art user experience coupled with access to the most recent machine learning frameworks such as Apache Spark, tensorflow, etc to unlock the value of machine data.
Note
This is an experimental feature under development.
Getting Started¶
Sumo Notebooks are organized as a docker container that assembles all dependencies in a single container. This simplifies installing and updating. A Sumo Notebooks container gets access to an organzation’s Sumo data store via Sumo’s REST API. For that purpose, we require you to create an access key for Sumo as described in this guide. After creating access credentials, please follow these steps to install and run the Sumo Notebooks container.
Running the Sumo Notebooks Docker Container¶
- Open a shell or terminal on your computer
1. Load the SumoLab docker container on your computer:
docker pull sumologic/notebooks:latest
Note
It is a prerequisite to have a working docker installed.
- Start the container. API access id and access key have to be submitted via command line to work with the Jupyter notebook but can be either submitted via the command line or entered via the Spark interpreter configuration menu in Zeppelin.
docker run -d -it -p 8088:8080 -e SUMO_ACCESS_ID='XXX' -e SUMO_ACCESS_KEY='XXX' -e SUMO_ENDPOINT='XXX' sumologic/notebooks:latest
- Open the Zeppelin UI and find some sample notebooks under the ‘Notebook’ drop down menu or see the ‘Demo.ipynb’ on opening Jupyter on the browser.
| Application | Ports | Link |
|---|---|---|
| Zeppelin | 8088 | http://localhost:8088 |
| Spark Web UI | 4040 | http://localhost:4040 |
| Tensorboard | XXXX | http://localhost:XXXX |
| Jupyter | 4000 | http://localhost:4000 |
This is it, happy coding!
Docker Container Environment Variables¶
There is a set of environment variables for Sumo Notebooks that can be set when starting the docker container. The docker push command provides the -e switch to define these variables.
| Variable | Description |
|---|---|
| SUMO_ACCESS_ID | Access Id token from Sumo, usually a base64url encoded string. |
| SUMO_ACCESS_KEY | Access key token from Sumo, usually a base64url encoded string. |
| SUMO_ENDPOINT | A https URL denoting the Sumo deployment to connect to. (Needed by Zeppelin) |
| ZEPPELIN_SPARK_WEBUI | This variable controls where the “Spark Job” link in a paragraph points. (Needed by Zeppelin) |
Setting the Access Keys¶
Sharing access id/key with the Sumo Notebooks container can be done using two methods:
- Submitting
SUMO_ACCESS_IDandSUMO_ACCESS_KEYenvironment variables to the container as shown in the previous section - Setting or changing the access id/key pair within the Zeppelin web UI as shown below. This is not available in Jupyter.
Step 1¶
Click on the username in the right top corner of the Zeppelin web UI. Scroll down or enter spark in the search bar to get to the Spark configuration page.
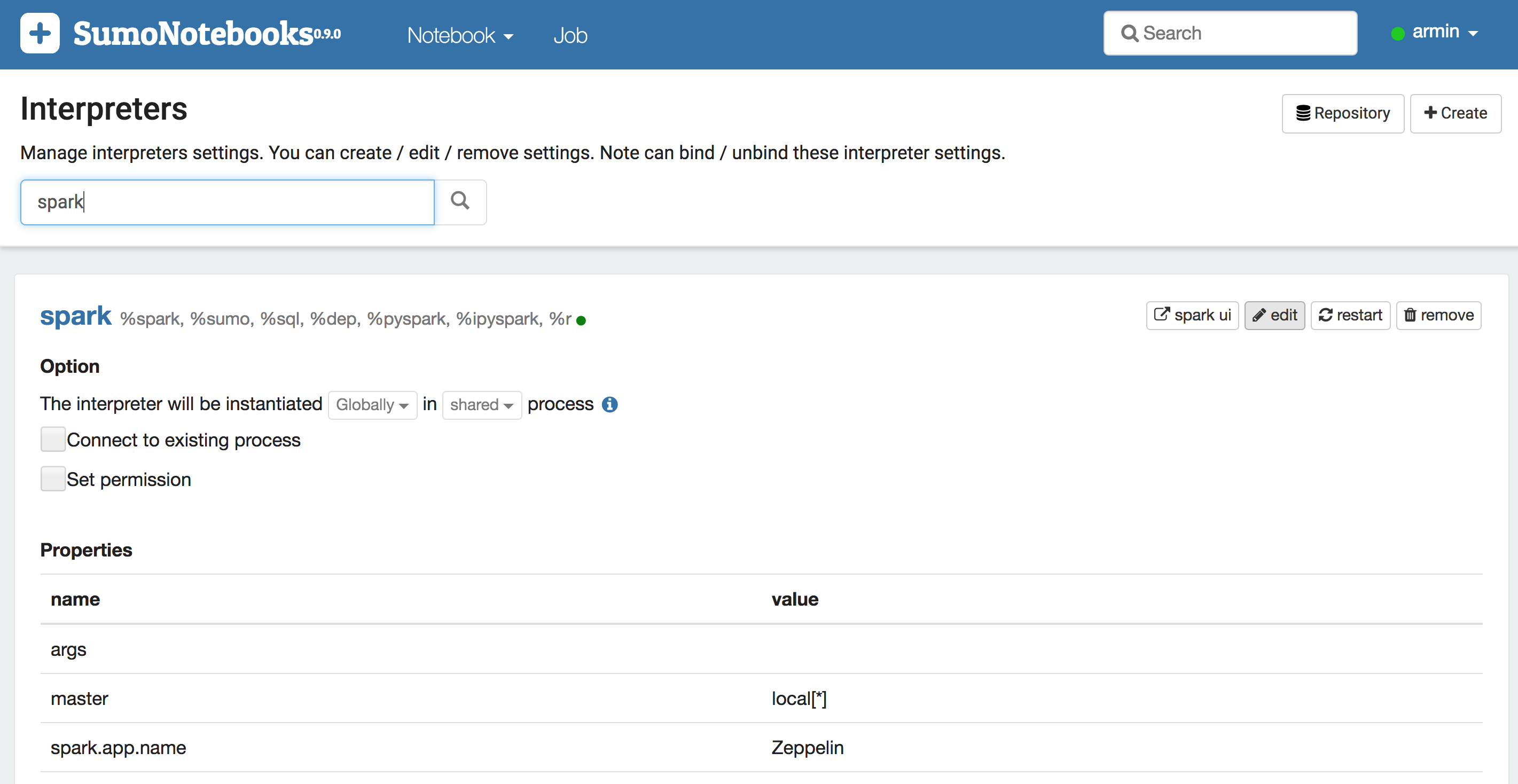
Open the Spark interpreter configuration page
Step 2¶
On the Spark configuration page click the edit button and then enter access id, access key, and http endpoint in the according text fields. An overview of the Sumo endpoints for the different deployments is listed on this page. Finally, save the configuration and the interprester will restart with the new configuration.
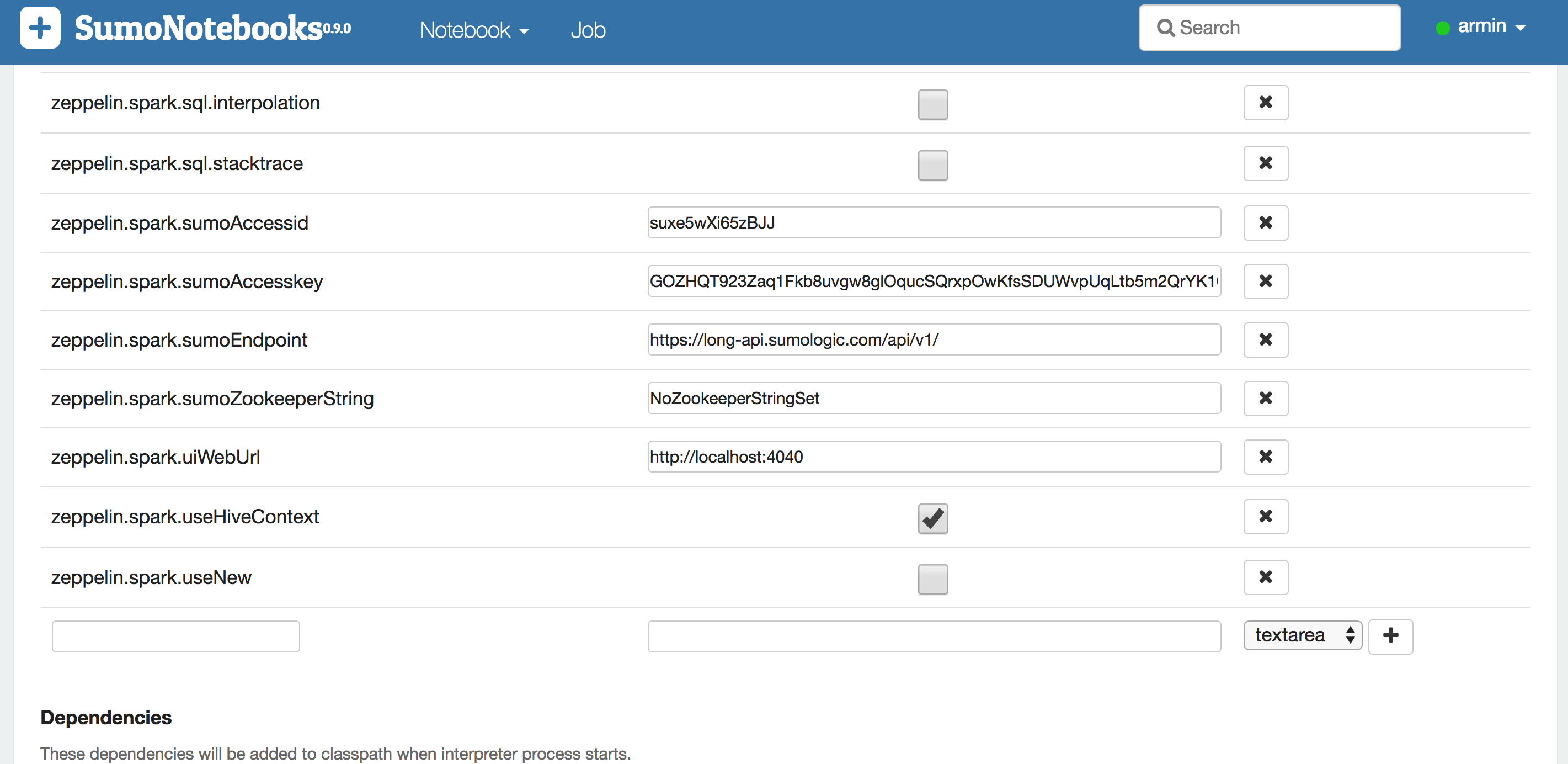
Enter the access id/key pair and save
Data Science Workflow¶
The foundational data structure for Sumo notebooks is a data frame. A typical data science workflow manipulates data frames in many ways. For instance, data frames might be transformed for feature generation and statistical analysis, or joined with another dataset for enrichment. Therefore, a Sumo notebook returns query results in a Spark dataframe. This enables users to tap into Spark’s development universe, or – using the toPandas method – switch over to a python-native approach for data analytics.
Data Exploration using Spark SQL¶
This workflow focuses on loading log data from Sumo and then performing data exploration using Spark SQL.
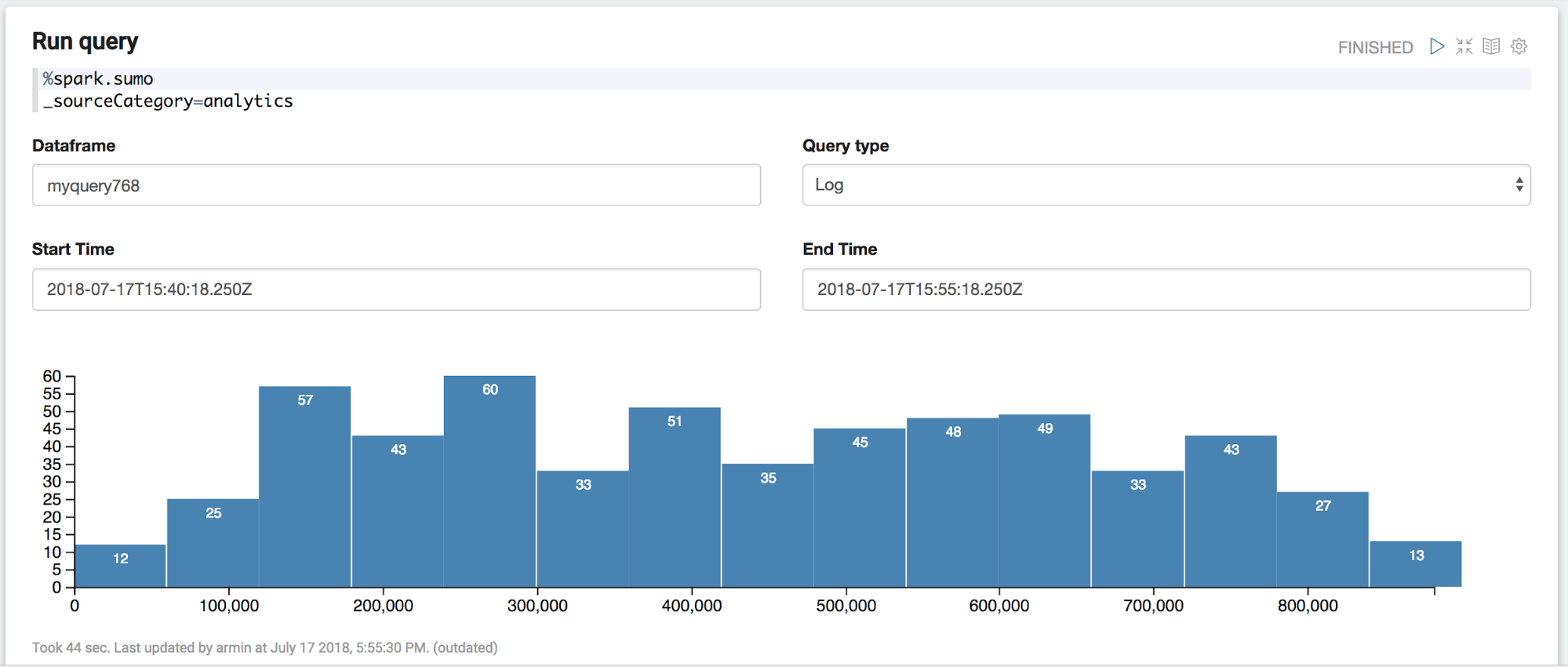
First thing is to instruct Zeppelin to use the Sumo interpreter by entering %spark.sumo in the first line of the paragraph. This annotation indicates that the paragraph is routed to the Sumo interpreter running in the backend. This interpreter checks the query, connects to Sumo using access id and access key and retrieves the data. The data is represented as a Spark DataFrame and can be used as such through the name displayed in the DataFrame field. In this example this is myquery768.
Note
In fact it uses a customized version of the sumo-java-client, therefore it has the same restrictions.
A DataFrame bound to this name exists in the scope of the Spark Scala shell, this is can be manipulated via the Spark Scala API. When sharing the reference through the Zeppelin context, it can also be used in PySpark (see next tutorial). The DataFrame as also registered as a temporary table in Spark SQL.
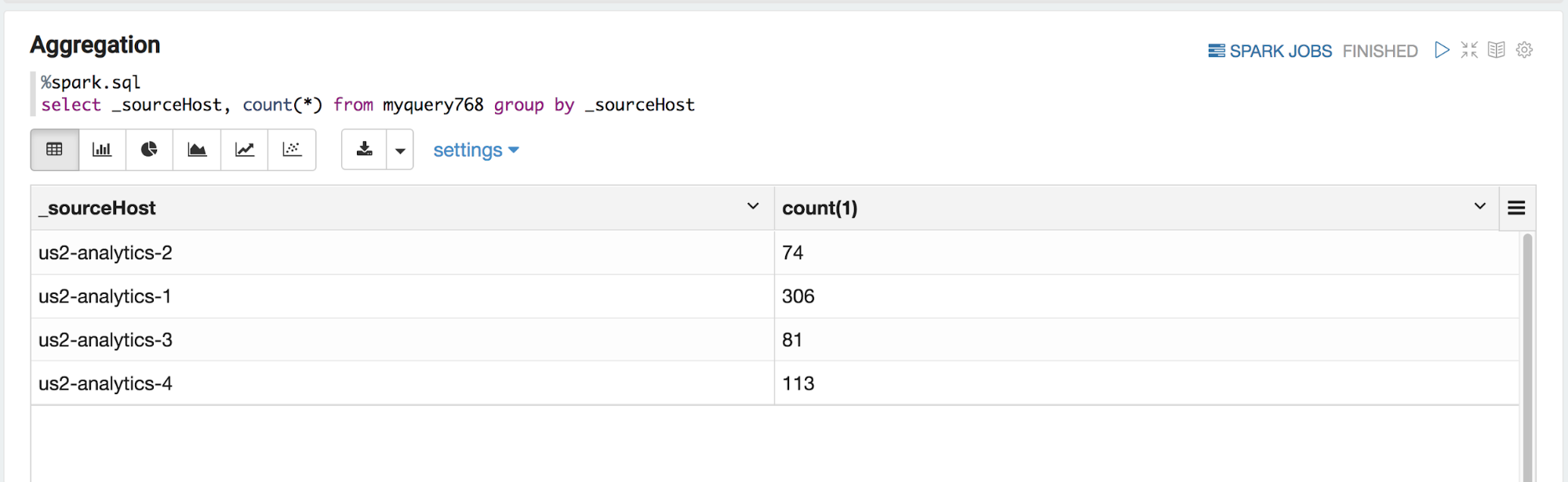
Starting the paragraph with %spark.sql designates the Spark SQL interpreter and SQL queries can be entered to explore the data. This example produces counts from raw data. Counting is a common pre-processing task for subsequent statistical learning task.
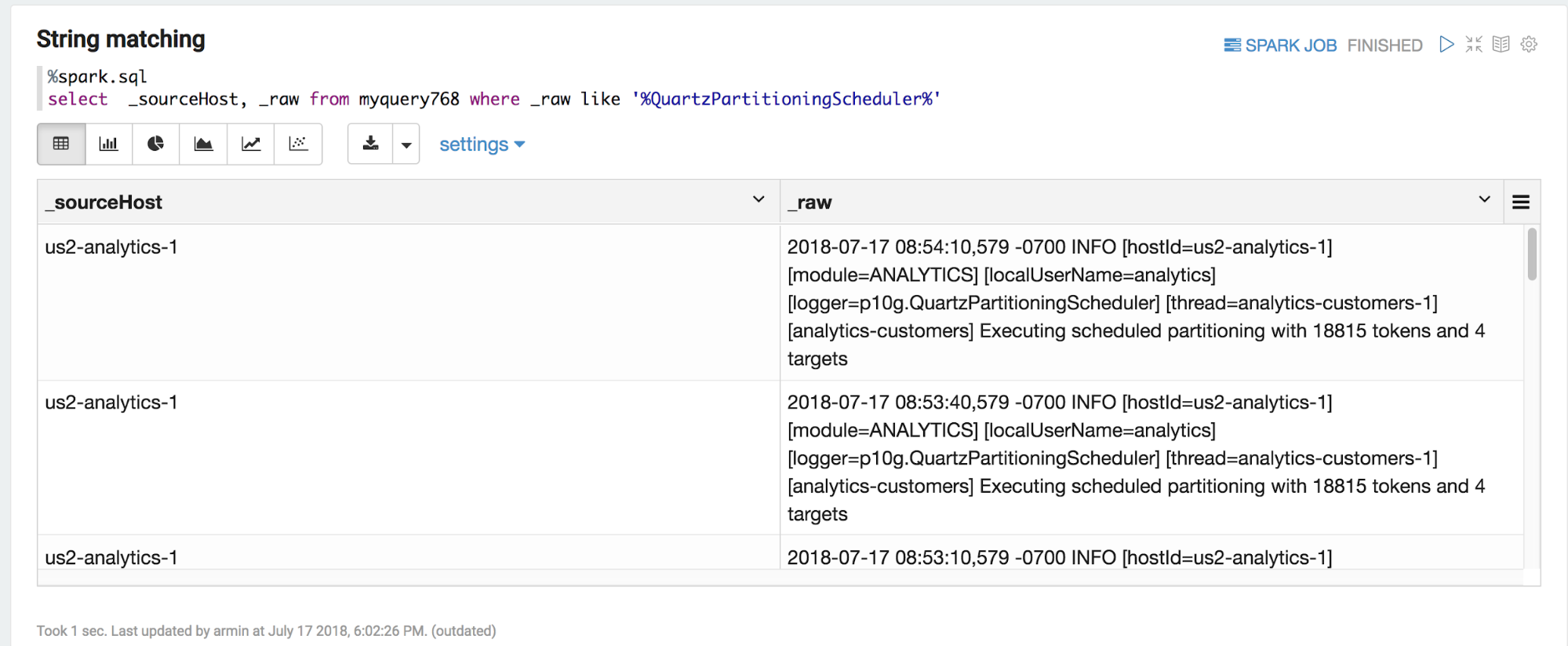
Another common operation on logs is string matching. Spark SQL’s SELECT provides a set of operations to filter and aggregate data.
Clustering Example¶
This example is about leveraging the python interpreter to perform a basic clustering operation on metrics data. As usual, %spark.sumo leads in a Sumo query. This time a metrics query is submitted. Metrics queries can be specified by selecting _Metrics_ via the drop down menu.
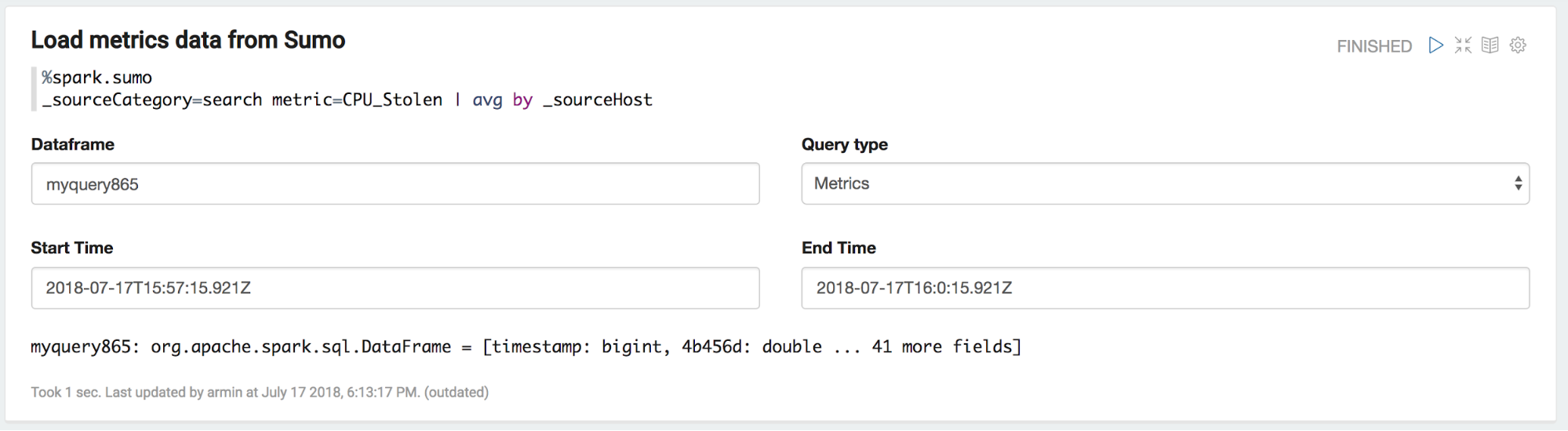
Similarly to the log queries, the result is a DataFrame. As this DataFrame lives in the Spark Scala world we need to share it via the Zeppelin context with the python interpreter
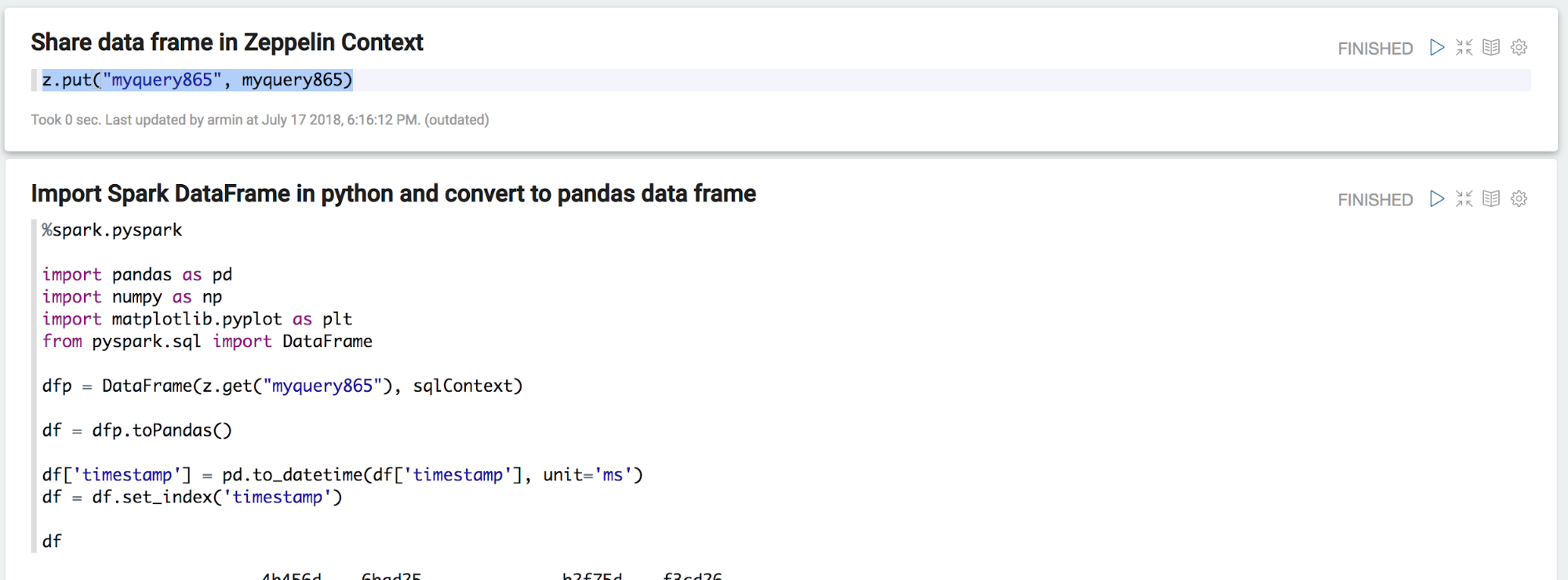
After retrieving the DataFrame in the python interpreter and loading it as a pandas data frame, the powerful world python machine learning frameworks opens up! First, some visual exploration using matplotlib reveals is done.
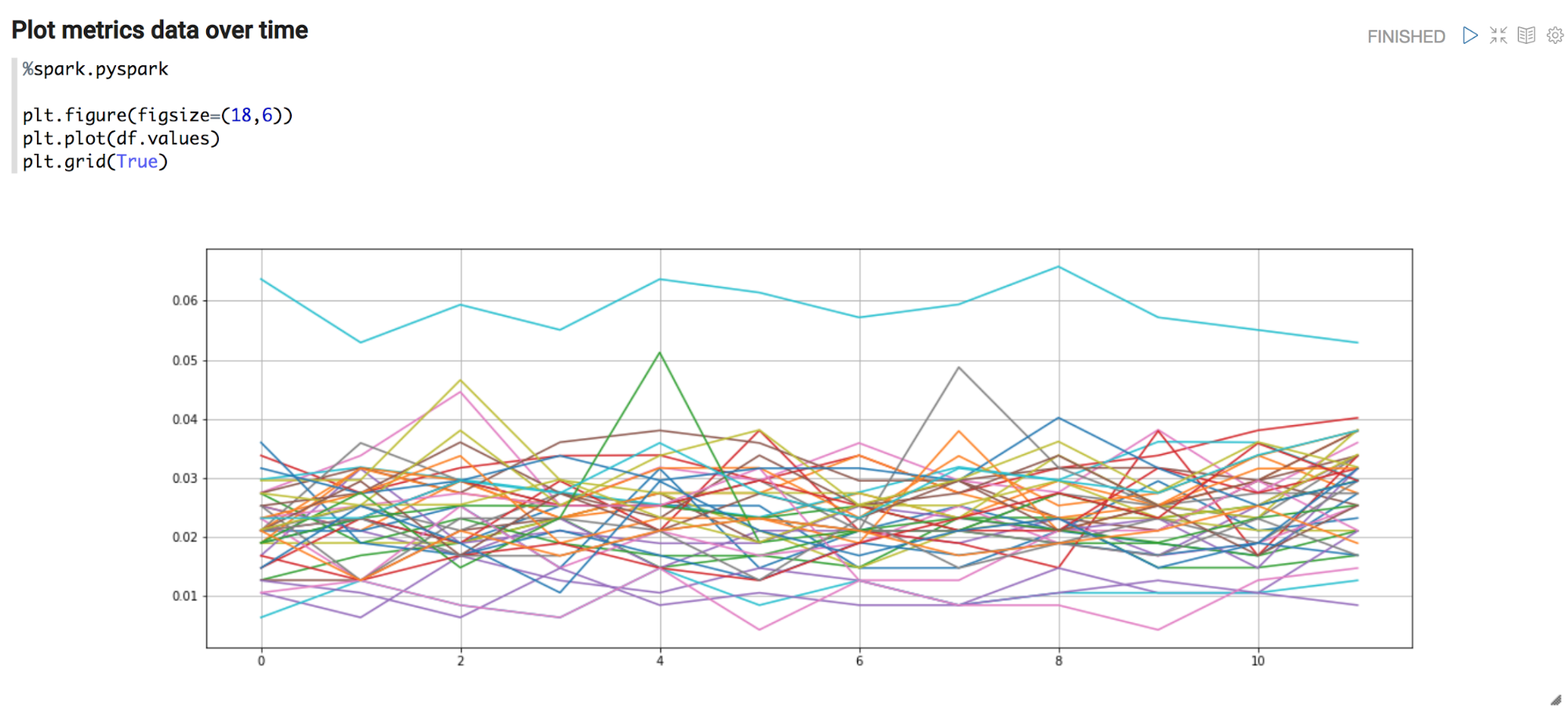
Next, each time series is featurized to simple (mean, std) pairs and plotted as a scatter plot. Visual inspection reveals that there might be some clusters!
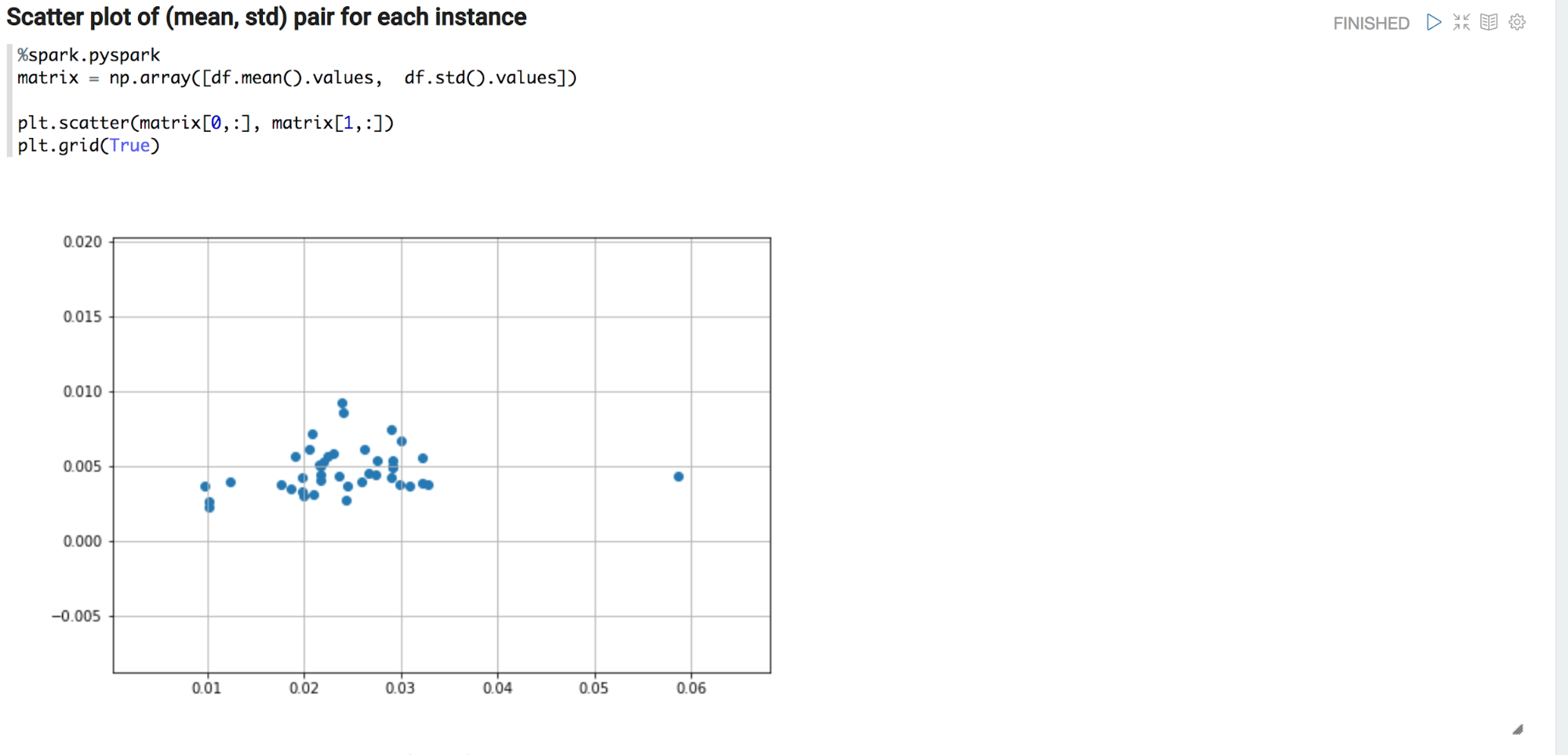
Using this intuition, a first try is to run the dbscan algorithm from the sklearn package.
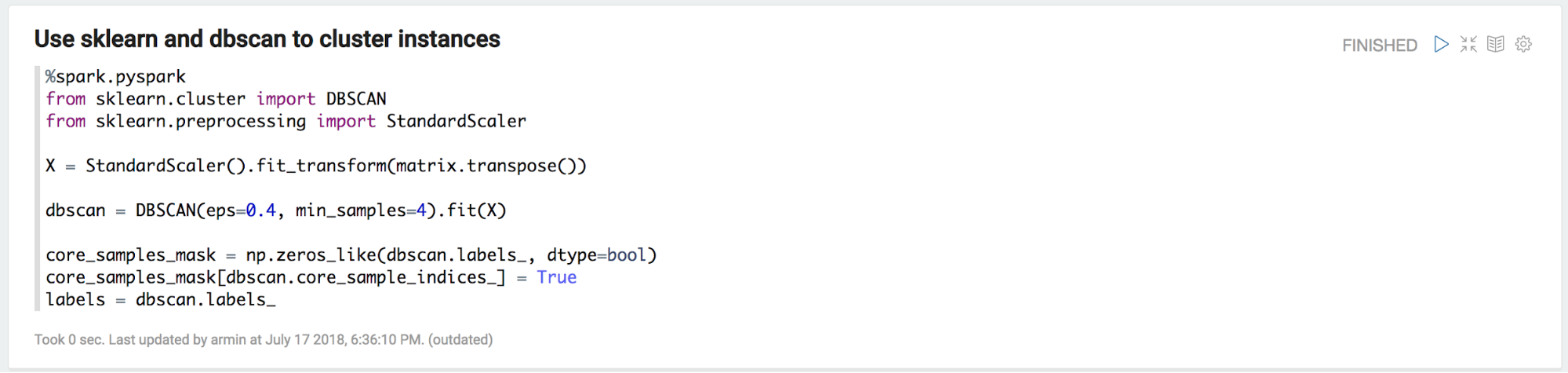
And there we are, yes there are a couple of clusters in the that particular metric.

Clustering Example using Jupyter¶
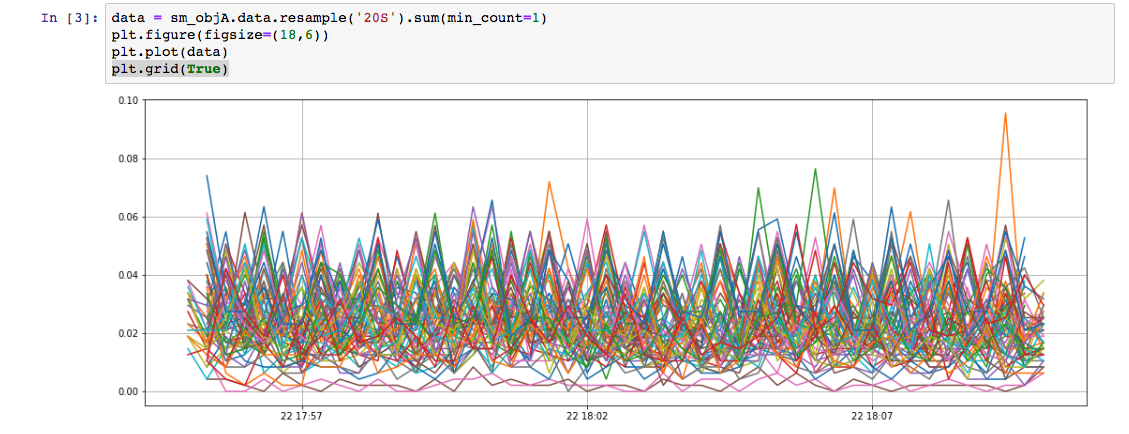
We can see the same clustering example shown above as executed on the Jupyter notebook.
We initialize a SumoLab object to get a simple interface to enter the query and time range parameters. Once added we can Run the query.

Once we have the data-frame we can follow the same procedure explained above to perform clustering of the data.
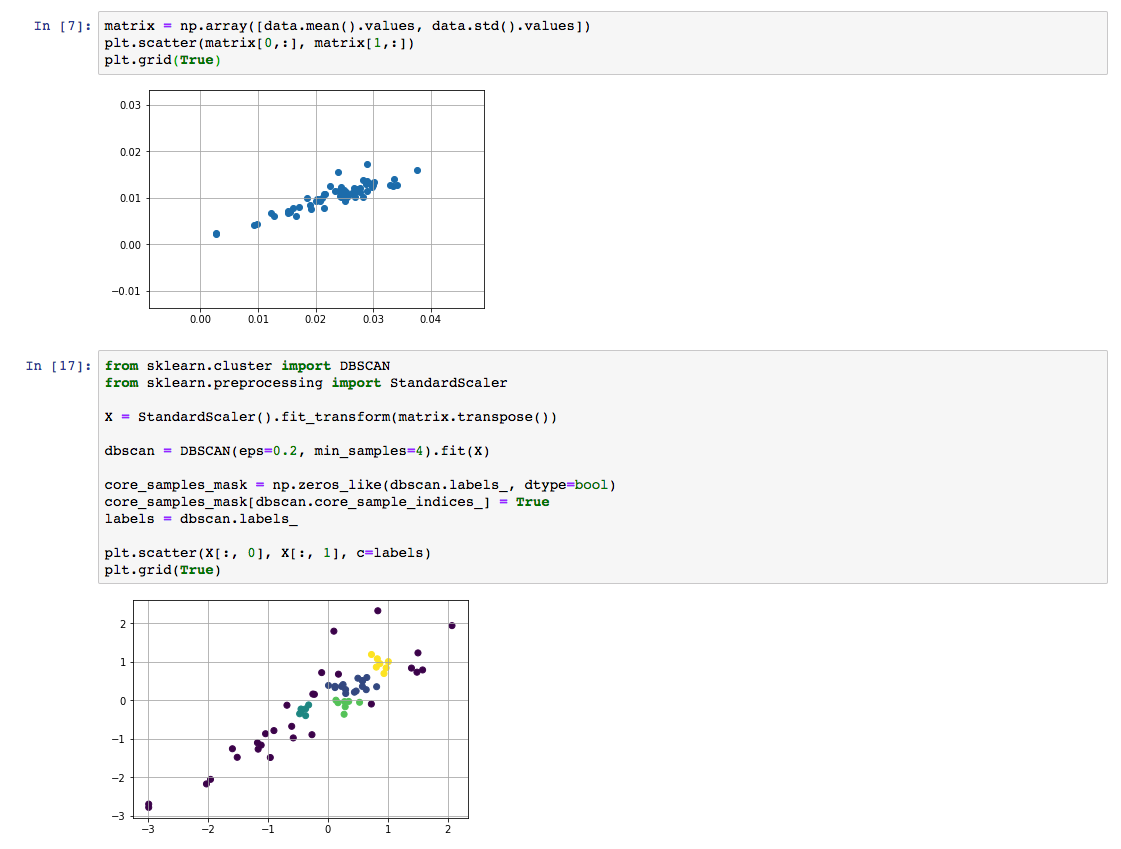
Troubleshooting¶
Common Errors¶
No data or exception:
- Make sure to have the right access credentials in place
TTransportException or timeout
- Restart the interpreter: Use black, top right gear for pulling up interpreter menu, then push restart icon on the left of the blue bar listing the interpreter group for spark, finally save on the bottom.
Debugging¶
The SparkSumoMemoryCache object is a key value store that holds the context of the most recent operations. It can be used to inquire on exceptions and results that are retrieve behind the scenes.
| Key | Type | Description |
|---|---|---|
| lastDataFrame | DataFrame | Holds a reference to the last data frame that has been created |
| lastLogQueryException | Exception | References the last exception (if any) that the log backend threw |
| lastMetricsQueryException | Exception | References the last exception (if any) that the log backend threw |
| lastMetricsDimensions | HashMap[String, String] | Dictionary to resolve the metrics column header to the actual dimensions |
| lastQueryJob | JobId | References the last job id returned from the search api |
| lastTriplet | QueryTriplet | Last processed query |
| metricsClient | SumoMetricsClient | Client used to retrieve metrics from Sumo |
| sumoClient | SumoClient | Client used to retrieve logs from Sumo |
| sparkSession | SparkSession | Spark session that is used to ingest the data |
Code example¶
val spark = SparkSumoMemoryCache.get("sparkSession").get.asInstanceOf[SparkSession]
Limitations¶
Current limits of the REST API are documented here.
Zeppelin is started with these parameters:
- ZEPPELIN_INTP_MEM=”-Xmx10g”
- SPARK_SUBMIT_OPTIONS=”–driver-memory 2g”